|
|
Ähnliche Berichte:
|
Papers in anderen sprachen:
|
|
|
informatik referate |
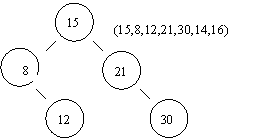
Das Suchen verkörpert die meistbenutzte Operation neben dem Anlegen. Sogar das Löschen ist eine Erweiterung des Suchens, denn bevor etwas gelöscht werden kann, muß es erst einmal gefunden werden. Zur Erklärung der Punkte Sequentielles und Binäres Suchen sei als Beispiel die Sozielversicherungsnummer angeführt. Sie hat insgesamt 12 Stellen. Die ersten 4 sind ein Code, die nachfolgenden 6 das Geburtsdatum im Format <TT:MM:JJ>
Wir unterscheiden Arrays (sortiert, unsortiert) und Bäume.
Bei diesem Suchverfahren wird jedes Feld des Arrays nacheinander durchgelaufen, bis das entsprechende Feld gefunden ist. Im Durchschnitt benötigt man dafür N/2 Operationen.
Best Case: das Erste Feld entspricht der gesuchten Sozialversicherungsnummer.
Worst Case: Das n-te Feld entspricht der gesuchten Sozialversicherungsnummer.
Eine neues Feld wird am Ende des Arrays angefügt (n+1).
n Felder

Für den hohen Durchschnitt der benötigten Operationen, die man bis zum Finden der gesuchten Sozialversicherungsnummer braucht (8 Mio Felder), ist das Sequentielles Suchen nicht gerade zweckführend. Eine andere Möglichkeit des Suchens ist
Bei unserem zweiten Versuch ist ein sortiertes Array vorliegend, d.h. die Felder sind aufsteigend sortiert. Man nennt das auch ein sortiertes Array. Neue Felder werden am Ende der Liste angefügt, unabhängig davon, ob es sich um eine Neugeburt oder um einen Zuwanderer handelt. Siehe auch Kapitel Indexreorganisation.
Funktion: Beim Binären Suchen wird die Anzahl der Felder immer weiter halbiert. Dadurch gelangt man viel schneller zum gesuchten Feld gegenüber dem Sequentiellen Suchen, da sich die Menge der zu suchenen Felder systematisch verkleinert. Bei 8 Mio. Felder entspricht das 23 Suchschritten.

![]()

![]()
Frage: Wie oft kann man n Felder halbieren? -> ld n
2^x = 8 Mio
x = ld 8 Mio
x 23
Average Case entspricht ungefähr dem Worst Case beim Binären Suchen (=2^x).
Beim Binären Suchen ist das Einfügen teurer als bei der Sequentiellen Sortierung, da die Reihenfolge erhalten werden muß.
Angenommen im Laufe eines Tages werden zu den 8 Mio. Feldern 30 neue hinzugefügt, so dauert die Suche der zuletzt angefügten Felder am Längsten. Das kommt daher, da zwar die ersten 8 Mio. Felder binär in 23 Schritten durchlaufen, die neu angefügten 30 Felder aber sequentiell im Worst Case bis zu 30 Mal zusätzlich abgeklappert werden.
Indexreorganisation wird meistens über Nacht oder zu Zeiten geringer Abfragen durchgeführt.
|
![]()
![]()
![]()
![]()
![]()


![]()
![]()
|
Knoten |
|
|
|
|
Tiefe |
|
|
|
|
Baum |
b.B. |
b.B. |
balancierter Baum |
|
Anmerkung: balancierter Baum: kurzes Suchen unbalancierter Baum: langes Suchen (bei vorsortierten Daten) |
2^(T+1) = K+1
T-1 = ld (K+1) -1
T= ld (K+1)-1
Erfunden von drei russischen Mathematikern (AVL steht für die drei Anfangsbuchstaben der Nachnamen der Mathematiker). Ein AVL Baum ist ein Baum, bei dem jeder einzelne Knoten eine Tiefendifferenz von ±1 hat.
Bei einem Degenerierten Baum ist die Struktur vollig unbalanciert. Jeder Knoten hat nur rechte bzw. linke Nachfoger.
Beispiel: das Wort W-U-R-M-L-I-E-D ist degeneriert.
Aber auch: S-O-N-N-I-G

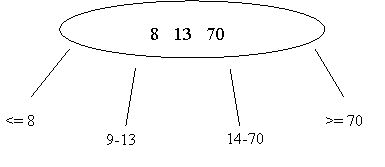
Beim 2-3-4 Baum hat man nmax 3 Zahlen, die daraus folgend in maximal 4 Einteilungen unterteilt werden können.
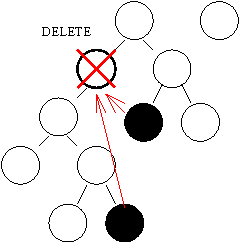
Ausgehend von der Grundlage, kleinere Kinder eines Knotens werden linke, größere jeweils rechts angeornet, ergibt sich folgendes Verfahren zum füllen der Lücke, an der ein Knoten gelöscht wurde. An Stelle des gelöschten Knotens können nur die Schwarz markierten Knoten stehen.

Operatoren beim Suchen:
-MINMAX
-MERGE (verschmelzen)
Beim Hashing gibt es nicht eine große, sondern viele kleine Suchstrukturen. Ein Beispiel wäre 26 (26 Buchstaben im Alphabet) Schülertabellen anzulegen.
Allgemein: Bevor man eine Strukur entwickelt entschließt man sich für eine der folgenden Operationsgruppen:
nur Hinzufügen & Löschen
oder MINMAX & Löschen
![]()
![]() andere Ansätze:
andere Ansätze:
![]() h1 erster Buchstabe
h1 erster Buchstabe
![]()
![]() h2 letzter Buchstabe
h2 letzter Buchstabe
![]() h3 länge des Namens
h3 länge des Namens
Ziel des Hashings ist es, gleichmäßige Hashfunktionen zu finden.
Einzelstruktur = Bucket (engl. Kübel)
Hashfunktion h(Pk Primary key)
Mittels eines Algorithmuses wird bestimmt, wo das Objekt eingeordnet wird. Der Algorithmus muß so aufgebaut sein, das die Verteilung gleichmäßig erfolgt. Der ASCII- Zeichensatz ist dabei ein erster Ansatz. Das Wort <R-O-T> besteht aus den drei unterschiedlichen Zeichencodes 200, 170 und 150. Man summiert die drei Codes, dividiert durch die Anzahl der Buchstaben im Alphabet (26!) und erhält einen Rest (modulo).
Das Verfahren ist aber nur dann optimal, wenn es mit 10 Datensätzen pro Bucket gefahren wird. Die Suche innerhalb des Buckets ist ein Array oder einfach eine verkettet Liste (Separate Chaining).
Verkettete
Liste

![]()
![]()
![]()
![]()
Linear Probing
Bei der Methode des Linear Probing verwenden wir pro Bucket einen Datensatz.
14730
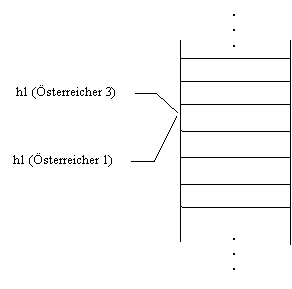
Was geschieht aber, wenn durch das Linear Probing ein Österreicher in ein Feld geschoben werden mußm daß schon besetzt ist? Die Lösung sind verschiedene Schrittweiten z.B. 2 Funktionen, auch genannt Double Hashing (gleichmäßigere Vererbung). Die Vorraussetzung für dieses Verfahren ist, daß es mehr Buckets als Datensätze geben muß.
Indirektes Suchen (Indirect Search)
(vgl. Buchindex am Ende eines Buches = Sortierte Datenstruktur mit einem Pointer auf Seiten)

INDEX= Für jedes Suchkriterium ein eigener Hilfsbaum (für schnelle Rückantwort)
für langsame Rückantwort T sequentiell
Statt dem Baum kann man auch eine geordnete Liste erstellen.
Laufzeit: ist die Zeit, die ein Algorithmus dazu benötigt eine Anzahl von n Elementen zu sortieren.
Stabilität: Ein Sortierverfahren wird stabil genannt, wenn es die Reihenfolge gleicher Schlüssel in der Datei beibehält, z.B. eine Menge von Schülern wird nach Noten (Schlüssel) sortiert. Bei einer stabilen Methode sind die Schüler noch immer in alphabetischer Reihenfolge in der Liste angeführt; bei einer instabilen ist von einer alphabetischen Reihenfolge keine Rede mehr.
Eine unsortierte bestehende Liste wird systematisch vom Anfang weg sortiert, indem die nächstkleinere Zahl links, die nächstgrößere Zahl rechts eingeordnet wird.
Der Insertion Sort ist sehr langsam, da nur benachbarte Elemente ausgetauscht werden.
30
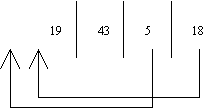
![]()
![]()
= Sortieren durch direktes Auswählen.
Der Selection Sort sucht aus einem Feld das kleinste Element und tauscht es gegen das an erster Stelle stehende Element. Dann wird das zweitkleinste Element gesucht und gegen das an zweiter Stelle stehende Element getauscht, u.sw. bis das gesamte Feld sortiert ist.
|
1. Durchgang |
|
|
|
|
|
|
|
|
2. Durchgang |
|
|
|
|
|
|
|
|
3. Durchgang |
|
|
|
|
|
|
|
|
4. Durchgang |
|
|
|
|
|
|
|
|
5. Durchgang |
|
|
|
|
|
|
|
|
6. Durchgang |
|
|
|
|
|
|
|
=Sortieren durch direktes Austauschen
Beim durchlaufen der Datei werden jeweils 2 Elemente paarweise verglichen. Wenn dabei das linke Element kleiner ist als das rechte, wird es vertauscht, wenn nicht, wird weitergegangen, bis das rechte Ende des Feldes erreicht ist.
Beim Insertion Sort sortiert man einen Index auf die Tabelle.
Der Shell Sort stellt das schnellste Sortierverfahren dar, wobei niemand weiß wieso. Es ist auch das einzige Sortierverfahren, das sich Mathematisch nicht erklären läßt und in keine Formel packen läßt.
Der Insertion Sort ist sehr langsam, weil nur benachbarte Elemente ausgetauscht werden. Wenn sich zum Beispiel das kleinste Element zufällig am Ende des Feldes befindet, so werden n Schritte benötigt, um es dorthin zu bekommen, wo es hingehört. Shellsort ist einfach eine Erweiterung von Insertion Sort, bei dem eine Erhöhung der Geschwindigkeit dadurch erzielt wird, daß ein Vertauschen von Elementen ermöglicht wird, die weit voneinander entfernt sind.
Es wird eine Schrittreihenfolge gewählt (z.B. 13-h). Vom Ersten Element ausgehend wird jedes h-te Element herausgenommen und in die richtige Reihenfolge gebracht. Dieser Vorgang wird mit jedem Element durchgeführt bis man am Ende angelangt ist. Dann wird eine neue Schrittreihenfolge gewählt (kleiner als die erste z.B.: 5-h) und der Prozeß beginnt von vorne.
Aus Versuchsreihen hat es sich herausgestellt, daß die Distanzen 1,4,13,40,121, (3n+1) das schnellste Sortierverfahren darstellen. Es ist allerdings möglich, den Shellsort mit anderen Folgen von Distanzen noch effizienter zu machen. Doch es ist für relativ große n schwer, das Programm um mehr als 20% schneller zu machen.
=rennt rekursiv durch
> 1000

|
Partitionselement gew. Zahl = 1000 |
|

|
Wenn unsortiert, rennen die Pointer unterschiedlich langsam (bei wenigen Elementen). |
Beim Quick Sort werden die 2 Teilfelder getrennt durchgegangen. Der linke Teil
von links nach rechts, der rechte Teil von rechts nach links. Es wird immer
dann unterbrochen, wenn ein Element kleiner ist als das Partitionselement ist.
Wenn die beiden im Diagramm kleinen, nach oben zeigenden Pfeile stehengeblieben
sind, werden die zwei Elemente vertauscht.
Der Nachteil des Quick Sort besteht darin, daß er rekursiv und störanfällig ist und daß er im Worst Case n² Operationen benötigt.
Eine sehr spezielle Situation, für die ein einfacher Sortieralgorithmus existiert, wenn eine Datei mit n Datensätzen viele verschiedene Zahlenschlüssel hat. Die Idee besteht darin, die Anzahl der Schlüssel mit jedem Wert zu ermitteln und dann die Ergebnisse der Zählung zu verwenden, um bei einem zweiten Durchlauf durch die Datei die Datensätze in die richtige Postition zu bringen.
| Referate über:
|
|
Datenschutz |
| Copyright ©
2025 - Alle Rechte vorbehalten AZreferate.com |
Verwenden sie diese referate ihre eigene arbeit zu schaffen. Kopieren oder herunterladen nicht einfach diese # Hauptseite # Kontact / Impressum |